¿Qué son los modelos de lenguaje grandes(LLMs)?
English version
Parece que las computadoras finalmente pueden entender nuestro idioma, ¡e incluso pueden responder! Estas IA son las últimas iteraciones de grandes modelos de lenguaje , también conocidos como LLM . Pero, ¿qué son exactamente estos LLM? ¿Cómo trabajan? ¿Y cómo se crean? Sumerjámonos en ello.

Modelos de lenguaje
En pocas palabras, un modelo de lenguaje es algo que puede generar texto de alguna manera . Los modelos de lenguaje tienen muchas aplicaciones. Por ejemplo, puede usarlos para analizar opiniones, marcar contenido tóxico, responder preguntas, resumir documentos, etc. Pero en principio, podrían ir mucho más allá de estas tareas habituales.
De hecho, imagina, por ejemplo, que tienes un modelo de lenguaje perfecto, algo que puede generar cualquier tipo de texto de tal manera que sea imposible distinguir si este texto es generado por una computadora o no. Entonces, podrías hacer muchas cosas con él. Por ejemplo, podría hacer que genere contenido clásico como correos electrónicos, artículos de noticias, libros y guiones de películas. Pero luego podría ir un paso más allá y hacer que genere programas de computadora o incluso software completo. Y luego, si eres realmente ambicioso, podrías hacer que genere artículos científicos. Si el modelo de lenguaje es realmente “perfecto”, estos artículos científicos no se distinguirían de los artículos reales, lo que significa que el modelo de lenguaje tendría que realizar una investigación real.
Por supuesto, un modelo de lenguaje tan perfecto está fuera de nuestro alcance en este momento, pero esto da una idea del poder potencial de estos sistemas. Los modelos lingüísticos no son “simplemente predicciones de texto”; son potencialmente mucho más que eso.
Veamos ahora cuáles son estos modelos en la práctica, comenzando desde el primer tipo de modelos de lenguaje ingenuo hasta los modelos de lenguaje grande basados en transformadores actuales.
Naive Language Models
Los modelos de lenguaje son modelos de aprendizaje automático, lo que significa que aprenden a generar texto. La forma de enseñarles (también conocida como la fase de entrenamiento) es darles un gran corpus de texto, a partir del cual descubren cómo imitar el proceso generativo que lo creó .
Ok, esto es bastante abstracto, pero en realidad es fácil crear un modelo de lenguaje ingenuo. Puede tomar un corpus de texto, dividirlo en cadenas de cierto tamaño y medir sus frecuencias. Esto es lo que obtuve con cadenas de tamaño 2:

Estos fragmentos se denominan n-gramas (donde n es su tamaño, por lo que n = 2 aquí). A partir de estos n -gramas puedes generar texto jugando al dominó. Comienza con un n -grama inicial, digamos “th”, y luego selecciona aleatoriamente, de acuerdo con las frecuencias medidas, un n -grama cuyo comienzo coincide con el final del n -grama inicial. Aquí podría ser “hi”, lo que haría que “th”+”hi”= “thi”. Luego puede continuar adjuntando un n -grama que comience con una “i”, y así sucesivamente para generar el texto completo. Como probablemente haya adivinado, estos modelos de n -gramas no generan el texto más coherente. Esto es lo que obtuve al continuar con el procedimiento:
thint w dicofat je r aton onecl omitt amen h s askeryz8, orbexademone ttexind thof thevevifoged tc hen f maiqumexin sl be mo taicacad theanw.soly. fanitoila, al
¡No es genial, por decir lo menos! Esto tiene sentido porque el modelo solo tiene en cuenta el carácter anterior para hacer su predicción del siguiente carácter: tiene una memoria muy pequeña. Si usamos n=4, obtenemos algo un poco mejor:
complaine building thing Lakers inter blous of try sure camp Fican chips always and to New Semested and the to have being severy undiscussion to can you better is early shoot on
Ahora hay algunas palabras escritas correctamente, ¡pero esto todavía no es genial! En teoría, aumentar más n mejorará las cosas, pero en la práctica, no podemos aumentar n mucho sin requerir un conjunto de datos gigantesco para entrenar el modelo . Una última cosa que podríamos hacer es usar palabras en lugar de caracteres como unidad base (la unidad base se llama token en la jerga de la PNL). Mejorará las cosas, pero tampoco conducirá a un texto muy coherente ya que estamos limitados a n <6 .
Estos modelos de lenguaje ingenuo siempre tienen poca memoria y, por lo tanto, no pueden generar un texto coherente más allá de unas pocas palabras . Sin embargo, tienen algunos casos de uso. Hasta hace unos años, se usaban mucho para la clasificación de textos y el reconocimiento de voz, y todavía se usan hoy en día para identificar idiomas, por ejemplo. Sin embargo, para tareas más avanzadas de comprensión y generación de textos, estos modelos no son suficientes. ¡Necesitamos redes neuronales!
Modelos de lenguaje basados en redes neuronales
Los modelos de lenguaje moderno se basan en redes neuronales (artificiales). Las redes neuronales son máquinas informáticas inspiradas en el cerebro que pueden aprender cómo realizar una tarea a partir de ejemplos de esa tarea . Esta forma de aprendizaje automático también se denomina aprendizaje profundo porque las redes se componen de varias capas computacionales (por lo tanto, son “profundas”). En una red neuronal, el aprendizaje se realiza repasando los ejemplos de la tarea y modificando iterativamente los parámetros de la red para optimizar el objetivo de la tarea . Puede pensar en estos parámetros como un montón de perillas que puede girar a la izquierda y a la derecha para mejorar el objetivo., excepto que es la computadora girándolas por ti, y sabe cómo girarlas todas a la vez en las direcciones correctas para mejorar las cosas (gracias al famoso algoritmo de retropropagación ). Entonces, la red revisa los ejemplos de la tarea (generalmente por lotes de unos pocos cientos de ejemplos) y optimiza el objetivo a medida que avanza. Aquí hay un ejemplo de un objetivo (llamado función de costo, cuanto más pequeño mejor) que se está optimizando::
A medida que se entrena el modelo, el costo disminuye, lo que significa que el modelo mejora en su tarea.
Ok, entonces en nuestro caso, queremos generar texto. La forma estándar actual de hacer esto es entrenar un modelo en la tarea de predecir la siguiente palabra a partir de palabras anteriores . Dado que hay varias palabras continuas posibles, el modelo aprende a asociar una probabilidad con cada palabra continua posible. Aquí hay una visualización de esta distribución de probabilidad para lo que viene después de “el gato se sentó en el”:
Una vez que tengamos dicho modelo predictivo, podemos generar una palabra muestreando sus probabilidades predichas, luego reinyectar esta palabra en la red, muestrear una nueva palabra, y así sucesivamente para generar texto. Se dice que dicho procedimiento generativo es autorregresivo porque la red reutiliza sus propias predicciones para hacer nuevas predicciones. Hay argumentos sobre por qué esta no es la mejor manera de hacerlo, pero actualmente es como se hace, ¡y funciona sorprendentemente bien!
Históricamente, el primer tipo de redes neuronales que se han utilizado para modelar el lenguaje son las redes neuronales recurrentes (también conocidas como RNN ) y, en particular, la arquitectura LSTM. Los RNN son como pequeñas máquinas que leen palabras una por una, actualizando una especie de estado mental en el proceso. Este estado mental es como un recuerdo y les permite, potencialmente, recordar cosas por un tiempo mientras generan texto. Los RNN pueden obtener un rendimiento mucho mejor que los modelos de n -gramas.
El RNN que más me impresionó en el momento de su creación fue A Neural Conversational Model , que presenta un LSTM entrenado por Google en 2015 sobre subtítulos de películas. Este modelo ya es, por supuesto, un gran modelo de lenguaje (¿quizás el primero?): tiene más de 300 millones de parámetros y ha sido entrenado en alrededor de mil millones de palabras. Dado que los subtítulos de las películas son conversaciones, puede usar fácilmente este modelo como un chatbot. Aquí hay ejemplos de respuestas de varias entradas humanas:
- Humano: como te llamas?
- Máquina: soy julia.
- Humano: ¿ cuándo naciste?
- Máquina: 20 de julio.
- Humano: mi nombre es david. Cuál es mi nombre ?
- Maquina: david.
- Humano: quien es skywalker?
- Máquina: es un héroe.
- Humano: ¿De qué color es el cielo?
- Máquina: azul.
- Humano: ¿De qué color es la sangre?
- Máquina: es lo mismo que un ojo morado.
Como puede ver, el modelo puede charlar, pero también sabe un poco sobre el mundo, ¡lo que aprendió únicamente al aprender a predecir el texto! Recuerdo estar fascinado por este hecho: aprender a predecir texto te obliga a entender el mundo (lo que no significa que sea fácil de ninguna manera). Sin embargo, este modelo tiene fuertes limitaciones. A menudo es incorrecto y, al igual que los modelos similares basados en LSTM, no puede generar textos extensos y coherentes. De hecho, en teoría, los RNN pueden recordar cosas durante mucho tiempo, pero en la práctica, tienden a olvidar las cosas con bastante rapidez: después de unas pocas docenas o cien palabras, comienzan a descarrilarse y se vuelven incoherentes .
Una solución a este problema de la memoria a corto plazo llegó en 2017 con un nuevo tipo de red neuronal llamada transformadores , que se basa en la operación de atención (que es esencialmente una operación de selección). Como un regalo para la vista, así es como se representan los transformadores en su artículo introductorio para la tarea de traducción:
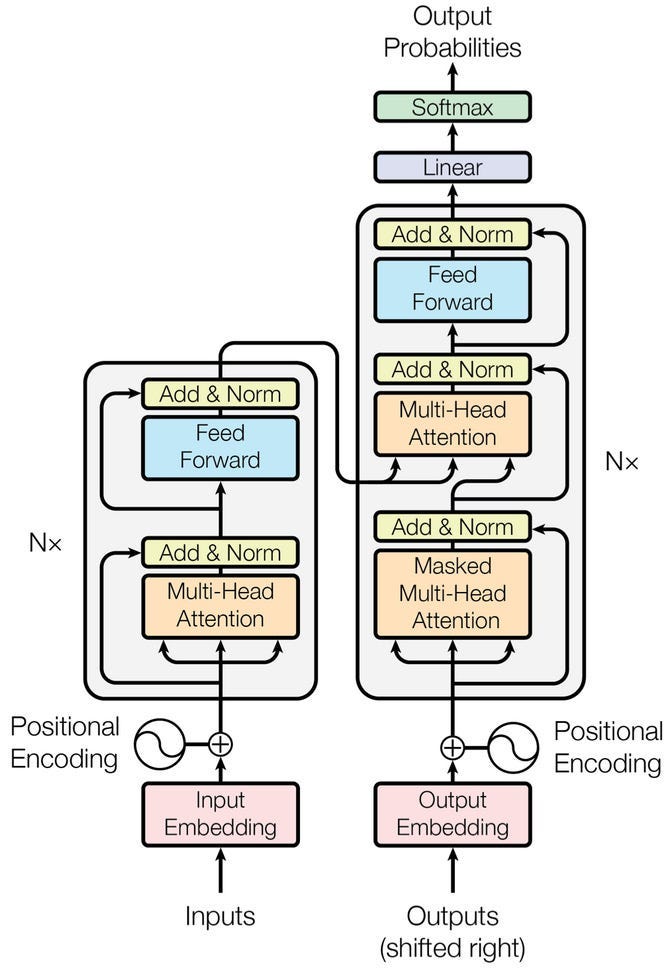
Hay muchas cosas interesantes que decir sobre esta arquitectura, pero la conclusión es que los transformadores funcionan muy bien para modelar texto y están bien adaptados para ser ejecutados por tarjetas gráficas (GPU) para procesar (y aprender de) grandes cantidades de datos. Es esta arquitectura transformadora la que condujo (o al menos contribuyó en gran medida) al surgimiento de modelos modernos de lenguaje grande .
Modelos modernos de lenguaje grande
La invención de los transformadores marcó el comienzo de la era de los grandes modelos de lenguaje modernos. Desde 2018, los laboratorios de IA han comenzado a entrenar modelos cada vez más grandes. Para sorpresa de muchos, ¡la calidad de estos modelos siguió mejorando! Aquí hay una visualización de estos modelos, de los cuales destacaremos los más notables:
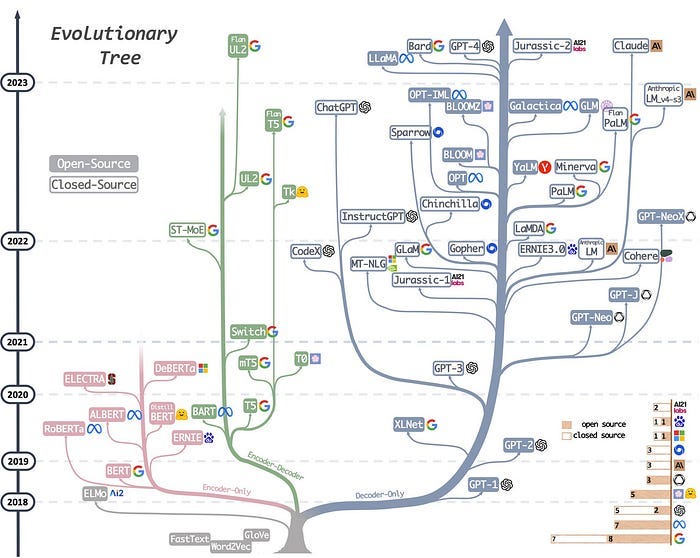
Hay tres sabores principales para estos modelos de lenguaje. Un tipo (que se muestra en rosa en la imagen, el grupo “solo codificador”) incluye LLM que son buenos para la comprensión del texto porque permiten que la información fluya en ambas direcciones del texto. Otro tipo (que se muestra en azul en la imagen, el grupo “solo decodificador”) incluye LLM que son buenos en la generación de texto porque la información solo fluye de izquierda a derecha del texto para generar nuevas palabras de manera eficiente y autorregresiva. Luego hay un tipo codificador-decodificador (mostrado en verde) que combina ambos aspectos y se usa para tareas que requieren comprender una entrada y generar una salida, como la traducción.
En su mayoría comenzó con el tipo de comprensión de texto. Primero con ELMo (aún usando RNNs) y luego el famoso BERT de Google, y sus descendientes como RoBERTa , que son todos transformers . Estos modelos suelen tener alrededor de unos pocos cientos de millones de parámetros (que corresponden a alrededor de 1 GB de memoria de la computadora), se entrenan con alrededor de 10 GB a 100 GB de texto (por lo general, unos pocos miles de millones de palabras) y pueden procesar un párrafo de texto en aproximadamente 0,1 segundos en una computadora portátil moderna. Estos modelos han mejorado drásticamente el rendimiento de las tareas de comprensión de textos, como la clasificación de textos, la detección de entidades y la respuesta a preguntas . Esto ya era una revolución en el campo de la PNL, pero era solo el comienzo…
Paralelamente al desarrollo de LLM de comprensión de texto, OpenAI comenzó a crear LLM de generación de texto basados en transformadores . Primero, GPT-1 en 2018 , que tenía 100 millones de parámetros, y luego GPT-2 en 2019 , que tiene hasta 1.500 millones de parámetros y está entrenado en 40 GB de texto. La creación de GPT-2 fue, al menos para mí, un momento crucial. Este es el tipo de texto que puede generar, a partir de un párrafo escrito por humanos:

Este es un inglés excelente, y el texto es coherente. Por ejemplo, el nombre del científico no cambia, lo que sería un problema clásico con los modelos basados en RNN. GPT-2 fue un salto de tal calidad en la generación que OpenAI originalmente decidió no lanzarlo al público por temor a un uso dañino . GPT-2 fue una señal de que los LLM estaban en el camino correcto. Tenga en cuenta que la forma de usar un modelo de lenguaje de este tipo es darle un texto inicial para que se complete. Este texto inicial se llama aviso .
Un año después (2020), OpenAI creó GPT-3 , un modelo con 175 mil millones de parámetros (¡700 GB de memoria de computadora para almacenar el modelo!). Este fue un aumento significativo en el tamaño y representó otra mejora significativa en términos de calidad de generación de texto. Además de su rendimiento mejorado, GPT-3 ha sido revelador en términos de cómo podríamos usar los LLM en el futuro.
Primero, GPT-3 es capaz de escribir código . Por ejemplo, puede usarlo para generar sitios web (muy) simples describiendo cómo debería verse el sitio web en el aviso. Aquí hay un ejemplo en el que le pedimos a GPT-3 que cree un botón en HTML:

Estas habilidades básicas de codificación no fueron tan útiles en ese momento, pero insinuaron que el desarrollo de software podría transformarse radicalmente en el futuro .
Otra perspectiva reveladora de GPT-3 es que puede realizar un aprendizaje en contexto , lo que significa que tiene la capacidad de aprender cómo realizar una tarea con solo mostrar ejemplos en un aviso. Esto significa que puede personalizar estos LLM sin tener que cambiar sus pesos, simplemente escribiendo un buen aviso. Esto ha abierto un nuevo tipo de PNL, puramente basado en indicaciones, que ahora es muy popular.
En general, GPT-3 reveló el potencial de las indicaciones como una nueva forma de hacer que las máquinas hagan lo que queremos que hagan a través del lenguaje natural.
Tenga en cuenta que GPT-3 es mucho más grande que GPT-2. Desde 2018, hemos sido testigos de un aumento extremo en el tamaño de los modelos. Aquí hay algunos LLM notables, junto con sus tamaños:
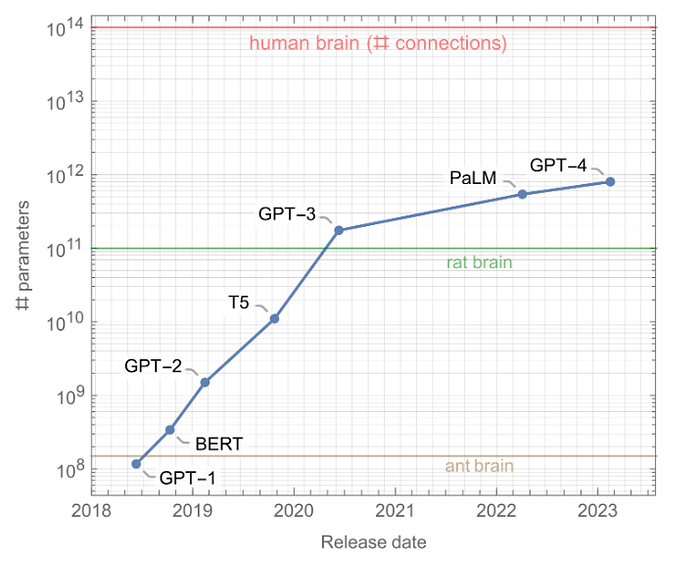
En dos años, la cantidad de parámetros se ha multiplicado por 1000, y los modelos más grandes actuales ( como GPT-4 ) están cerca de 1 billón de parámetros. Este aumento fue impulsado por el hecho de que el rendimiento siguió mejorando con el tamaño del modelo, sin estancamiento a la vista. Estos modelos son tan grandes que podríamos tener la tentación de compararlos con nuestro cerebro, que tiene alrededor de 100 mil millones de neuronas, cada una conectada a unas 1000 otras neuronas en promedio, es decir, alrededor de 100 billones de conexiones en total. En cierto sentido, los LLM más grandes siguen siendo 100 veces más pequeños que nuestro cerebro. Por supuesto, esta es una comparación muy vaga ya que nuestro cerebro y los LLM actuales usan arquitecturas y procedimientos de aprendizaje muy diferentes.
Otra métrica interesante sobre estos modelos es la cantidad de palabras que “leen” durante su fase de entrenamiento:
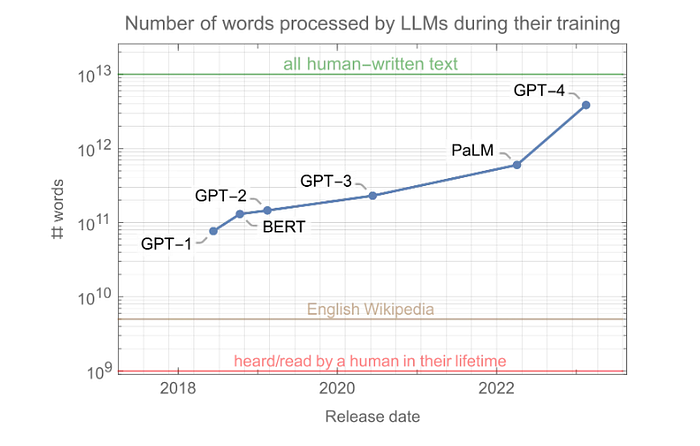
Como puedes ver, es mucho. ¡Estos modelos ven más de 100 mil millones de palabras durante su entrenamiento, que es más de 100 veces lo que un humano escuchará o leerá en su vida! Esto muestra cuán diferentes son estas redes neuronales de nuestro cerebro. Aprenden mucho más lentamente que nosotros, pero tienen acceso a muchos (¡muchos!) más datos.
Tenga en cuenta que la cantidad de palabras que encuentran los LLM durante su capacitación no aumentó tanto como el conteo de parámetros (solo un factor de 3 entre GPT-1 y GPT-3). Esto se debe a que, en cambio, se priorizó el tamaño del modelo y resultó ser un pequeño error. Los últimos modelos no son mucho más grandes que GPT-3, pero se entrenan procesando muchas más palabras que GPT-3.
El problema con esta sed de datos es que existe un límite estricto en la cantidad total de texto útil disponible (unos pocos billones de palabras) y los modelos se están acercando a él. Todavía existe la posibilidad de recorrer todo este texto, pero esto da como resultado rendimientos decrecientes en términos de rendimiento del modelo . En general, podemos considerar que existe un límite efectivo de algunas decenas de billones de palabras para ser procesadas por la red durante su fase de entrenamiento, aproximadamente 10 veces más de lo que experimentó GPT-4.
El otro problema, que surge del entrenamiento de modelos más grandes con más datos, es que el costo de la computación está aumentando. Estos son los costos de cálculo estimados para entrenar los modelos mencionados anteriormente:
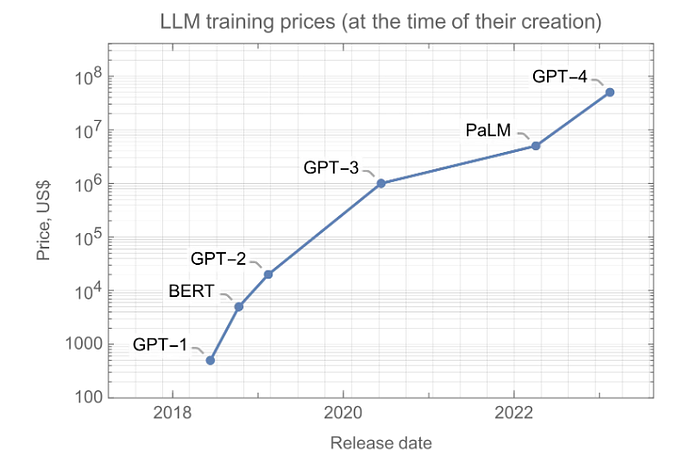
Para superar significativamente a los modelos actuales, la próxima generación de modelos debería requerir cientos de millones de dólares en computación , lo que aún tiene sentido dados los beneficios que brindan estos modelos, pero no obstante es un problema.
Ampliar los modelos es cada vez más difícil. Afortunadamente, la ampliación no es la única forma de mejorar los LLM. A fines de 2022, una innovación desencadenó otra revolución, con un impacto mucho más allá del mundo de la PNL esta vez.
LLM de bots conversacionales y adaptados a las instrucciones
GPT-3 reveló el potencial de las indicaciones, pero escribir indicaciones es difícil. De hecho, los LLM clásicos están entrenados para imitar lo que ven en la web, por lo que para crear un buen aviso, debe descubrir cuál sería, en la web, el texto inicial que conduciría a la salida deseada. Este es un juego extraño y una especie de arte para encontrar la formulación correcta. Necesita cambiar la redacción, fingir que es un experto, mostrar ejemplos de cómo pensar paso a paso, etc. Esto se llama ingeniería rápida y dificulta el uso de estos LLM.
Para abordar esto, los investigadores han estado explorando cómo modificar estos LLM básicos para seguir mejor las instrucciones humanas. Hay dos formas principales de hacer esto. El primero es usar pares de instrucciones-respuestas escritos por humanos y luego ajustar (es decir, continuar entrenando) el LLM base en este conjunto de datos. La segunda forma es hacer que el LLM genere varias respuestas posibles, hacer que los humanos califiquen estas respuestas y luego ajustar el LLM en este conjunto de datos mediante el aprendizaje por refuerzo. Esto se conoce como el famoso procedimiento de aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF) . También es posible combinar ambos enfoques, que es lo que hizo OpenAI con InstructGPT y luego con ChatGPT.

Paso de ajuste de instrucciones de InstructGPT y ChatGPT. De https://openai.com/blog/chatgpt (modificado de https://arxiv.org/abs/2203.02155 )
El uso de ambas técnicas juntas da como resultado un LLM ajustado a las instrucciones que es mucho mejor para seguir las instrucciones humanas que el modelo base y, por lo tanto, mucho más fácil de usar.
Los LLM ajustados a las instrucciones ya eran excelentes, pero había un último paso para convertir estos LLM en algo que todos pudieran realmente usar: hacer una versión de chatbot de ellos. OpenAI logró esto al lanzar ChatGPT en diciembre de 2022, un chatbot basado en GPT-3.5. Ha sido creado de la misma manera que InstructGPT, pero esta vez utilizando conversaciones completas en lugar de solo pares de instrucciones y respuestas.
Después del lanzamiento de ChatGPT, presenciamos una serie de nuevos chatbots basados en LLM. OpenAI mejoró ChatGPT mediante el uso de GPT-4 en lugar de GPT-3.5, Anthropic lanzó Claude , Google lanzó Bard , Meta lanzó LLaMA y actualmente se están lanzando varios LLM de código abierto. Esta es una verdadera explosión, y creo que conducirá a muchas aplicaciones emocionantes, algo con lo que nosotros, en NuMind, ayudaremos.
Dos meses después de su lanzamiento, ChatGPT ya tenía 100 millones de usuarios, el crecimiento de producto más rápido de la historia. La gente lo usa para escribir correos electrónicos a partir de viñetas, para reformular texto, para resumir texto, para escribir código o simplemente para aprender algo, una tarea que los motores de búsqueda tenían el monopolio hasta entonces. El lanzamiento de ChatGPT fue un punto de inflexión en la historia de los LLM. Todos se dieron cuenta del potencial de estos LLM y comenzó una “carrera de IA”, que involucró a los principales laboratorios de IA del mundo y varias nuevas empresas.
Tenga en cuenta que la repentina y generalizada accesibilidad de los LLM también viene con la preocupación de que se utilizarán para hacer cosas dañinas. Es por eso que una gran parte de la creación de estos chatbots abiertos basados en LLM se trata de hacerlos “seguros” (o “alinearlos con los valores humanos”), lo que significa que no deberían ayudarlo a construir una bomba, por ejemplo. Por el momento, a menudo hay formas de engañar a los chatbots y eludir sus medidas de seguridad, pero estas medidas de seguridad están mejorando con el tiempo. Creo que será muy difícil engañarlos eventualmente.
¿Que sigue?
Los LLM han mejorado mucho en los últimos años, y hay más esfuerzos que nunca dirigidos a mejorarlos aún más. Entonces, ¿qué debemos esperar para los próximos años? Es difícil predecir el futuro, pero aquí hay algunos pensamientos.
Una dirección obvia es continuar ampliando los tamaños de los modelos y la cantidad de datos de entrenamiento. Esto ha funcionado extremadamente bien en el pasado y aún debería permitir algunas mejoras. El problema es que los costos de capacitación se están volviendo prohibitivos (> $ 100 millones). Mejores GPU y nuevo hardware especializado ayudarán, pero su desarrollo y producción lleva tiempo. Además, los modelos más grandes ya iteran sobre todos los libros y sobre toda la web, lo que significa que estamos llegando al límite en términos de datos de entrenamiento disponibles (la llamada “crisis de tokens”). Entonces, con seguridad, no habrá una explosión de números de parámetros en los próximos años como vimos en los últimos años. Los modelos más grandes deberían establecerse por debajo de 1 billón de parámetros este año y luego experimentar un crecimiento anual del 50% como máximo.
Otra dirección obvia es ir más allá de los modelos de lenguaje puro e incorporar imágenes o incluso videos en los datos de entrenamiento , es decir, entrenar modelos multimodales . Aprender de tales datos podría ayudar a estos modelos a comprender mejor el mundo. GPT-4 ha sido entrenado tanto en imágenes como en texto, y mejoró un poco el rendimiento (pero no tanto). El entrenamiento en videos puede cambiar el juego, pero requiere mucho cálculo. Esperaría que tuviéramos que esperar más de 2 años antes de ver el primer modelo de “lenguaje” realmente grande entrenado en videos.
Ampliar o volverse multimodal requerirá muchos cálculos. Una solución para mitigar este problema es usar mejores arquitecturas neuronales y procedimientos de entrenamiento que sean menos intensivos en computación o que puedan aprender con menos datos (y nuestro cerebro es una prueba de que es posible). Lo más probable es que la memoria tipo RNN regrese porque es muy eficiente en el tiempo de ejecución (ver, por ejemplo, la reciente arquitectura RWKV ). Pero también podríamos ver un cambio más drástico, como los LLM que no generan de manera autorregresiva sino de arriba hacia abajo.– básicamente tomar decisiones (aleatorias) antes de generar palabras — lo que parece ser algo más lógico cuando lo piensas (y es cómo las redes neuronales generan imágenes en este momento). Es difícil saber cuándo se desarrollarán tales nuevas arquitecturas/métodos, pero no me sorprendería si sucede en los próximos años y conduce a LLM mucho mejores.
Otra dirección para mejorar es hacer un seguimiento de la ruta de ajuste de instrucciones e involucrar a muchos más humanos en la “educación” del LLM (también conocido como alineación de la IA). Esto podría ser realizado por laboratorios privados de IA, pero también podría ser un proyecto similar a Wikipedia más colaborativo para mejorar y alinear las capacidades de LLM de los modelos abiertos. Sobre ese tema, también podríamos querer desviarnos del RLHF tradicional y hacer que las personas simplemente discutan con el modelo para enseñarlo, como lo haríamos con los niños. No estoy seguro de la línea de tiempo para tal proyecto, ¡pero he estado pensando en esto por un tiempo y me encantaría verlo realidad!
Ok, solo hablamos sobre mejorar el modelo real, pero hay formas de mejorar los LLM sin siquiera cambiar el modelo. Una de esas formas es dar a los LLM acceso a herramientas. Dicha herramienta puede ser un motor de búsqueda para encontrar información precisa o una calculadora para hacer operaciones matemáticas básicas. También puede ser una base de conocimientos junto con un motor de inferencia (un componente clásico de la IA simbólica) como Wolfram Alpha para encontrar hechos y realizar razonamientos lógicos u otros tipos de cálculos en los que las redes neuronales no son muy buenas. Y, por supuesto, esta herramienta puede ser un entorno de programación completo para escribir y ejecutar código. Los LLM pueden usar estas herramientas generando tokens especiales (palabras) que desencadenan llamadas a la API y luego insertan la salida de la API en el texto generado:
Ejemplos de un LLM utilizando herramientas. De https://arxiv.org/abs/2302.04761
Esta tendencia de herramientas ya comenzó (consulte, por ejemplo, los complementos de ChatGPT , la biblioteca LangChain y el documento de Toolformer ) y creo que se convertirá en el centro de los LLM.
Otra dirección es usar los LLM de una manera más inteligente para que sean mejores en la realización de tareas. Esto se puede lograr mediante indicaciones inteligentes o un procedimiento más avanzado. Un ejemplo simple de esto es pedirle al LLM que piense paso a paso. Esto se denomina indicaciones de cadena de pensamientos y mejora el rendimiento de los LLM en tareas que requieren lógica . Aquí hay un ejemplo de cómo incitar a un LLM a pensar paso a paso:

De manera similar, puede pedirle al LLM que reflexione sobre su resultado, lo critique y lo modifique de manera iterativa. Estos tipos de procedimientos iterativos pueden mejorar significativamente el rendimiento, especialmente para generar código. Luego, puede ir aún más lejos y crear agentes totalmente autónomos que puedan administrar una lista de tareas e iterar sobre estas tareas hasta alcanzar el objetivo principal (consulte AutoGPT y BabyAGI ). Estos agentes autónomos no están funcionando bien en este momento, pero mejorarán, y es difícil exagerar cuán impactantes pueden llegar a ser.
Por cierto, dado que un LLM puede mejorar sus respuestas a través de estos procedimientos (cadena de pensamientos, críticas iterativas, etc.), podemos crear pares de instrucción-respuesta usando estos procedimientos y luego ajustar el LLM en estos pares para para mejorar su rendimiento. Este tipo de superación personal es posible (ver, por ejemplo, aquí ) y creo que tiene mucho potencial. Podríamos, por ejemplo, imaginar el modelo discutiendo consigo mismo para volverse más autoconsistente, una especie de procedimiento de autorreflexión. Esta dirección probablemente dará otro impulso al desempeño de LLM.
Ok, probablemente me perdí otras direcciones para mejorar, pero detengámonos aquí. En general, no podemos saber con certeza qué nos depara el futuro, pero está claro que los LLM llegaron para quedarse. Su capacidad para comprender y generar texto los convierte en una pieza fundamental de la tecnología. Incluso en su forma actual, los LLM desbloquearán muchas aplicaciones, la más obvia son los asistentes digitales que realmente funcionan, y en el escenario más loco, incluso podrían llevarnos a la creación de algún tipo de superinteligencia, que es un tema para otro momento!
