Una guía paso a paso para crear un portafolio de proyectos de Data Science
Especialmente si está comenzando a lanzarse como científico de datos, primero querrá demostrar sus habilidades a través de ideas interesantes de proyectos de ciencia de datos que pueda implementar y compartir. Esta guía paso a paso le muestra cómo realizar este proceso.

Cuando aprendí codificación y ciencia de datos como estudiante de negocios a través de cursos en línea, no me gustó que los conjuntos de datos estuvieran compuestos de datos falsos o que se resolvieran antes, como Boston House Prices o el conjunto de datos Titanic en Kaggle.
En este blog, quiero mostrarles cómo desarrollo ideas interesantes para proyectos de ciencia de datos y las implemento paso a paso , como explorar el foro de viajero frecuente más grande de Alemania, Vielfliegertreff. Si tiene poco tiempo, no dude en pasar directamente a la conclusión.
Paso 1: Elige el tema que te pasiona
Como primer paso, pienso en un proyecto potencial que cumpla los siguientes tres requisitos para que sea el más interesante y agradable:
- Resolviendo mi propio problema o pregunta interesante.
- Conectado a algún evento reciente para ser relevante o especialmente interesante.
- No se ha resuelto ni cubierto antes.
Como estas ideas aún son bastante abstractas, déjame darte un resumen de cómo mis tres proyectos cumplieron con los requisitos:

Como principiante, no se esfuerce por alcanzar la perfección, sino que elija algo sobre lo que sienta genuina curiosidad y escriba todas las preguntas que desee explorar en su tema.
Paso 2: Comience a recopilar su propio conjunto de datos
Dado que cumplió con mi tercer requisito, no habrá ningún conjunto de datos disponible públicamente, y tendrá que reunir los datos usted mismo. Buscando un par de sitios web, hay 3 marcos principales que uso para diferentes escenarios:

Para Vielfliegertreff, utilicé scrapy como marco por las siguientes razones:
- No había elementos habilitados para JavaScript que ocultaran datos.
- La estructura del sitio web era compleja, teniendo que ir de cada tema del foro, a todos los hilos y de todos los pasos a todas las páginas del sitio web de publicaciones. Con scrapy, puede implementar fácilmente una lógica compleja que genere solicitudes que conduzcan a nuevas funciones de devolución de llamada de una manera organizada.
- Hubo bastantes publicaciones, por lo que rastrear todo el foro definitivamente llevará algo de tiempo. Scrapy te permite rastrear sitios web de forma asincrónica a una velocidad increíble .
Para darle una idea de lo poderoso que es scrapy, rápidamente comparé mi MacBook Pro (13 pulgadas, 2018, cuatro puertos Thunderbolt 3) con un procesador Intel Core i5 de cuatro núcleos a 2,3 GHz que pudo raspar alrededor de 3000 páginas /minuto:

Para ser amable y no bloquearse, es importante que haga un scraping lentamente, por ejemplo, habilitando la función de aceleración automática de scrapy . Además, también guardé todos los datos en una base de datos SQL lite a través de una canalización de elementos para evitar duplicados y encendí el registro de cada solicitud de URL para asegurarme de no poner más carga en el servidor si detengo y reinicio el proceso de scraping.
Saber cómo hacer scrape te da la libertad de recopilar conjuntos de datos por ti mismo y te enseña conceptos importantes sobre cómo funciona Internet, qué es una solicitud y la estructura de HTML / XPath.
Para mi proyecto, terminé con 1,47 GB de datos, cerca de 1 millón de publicaciones en el foro.
Paso 3: limpieza de su conjunto de datos
Con su propio conjunto de datos desordenado y scraping, viene la parte más desafiante del proyecto, donde los científicos de datos dedican en promedio el 60% de su tiempo :
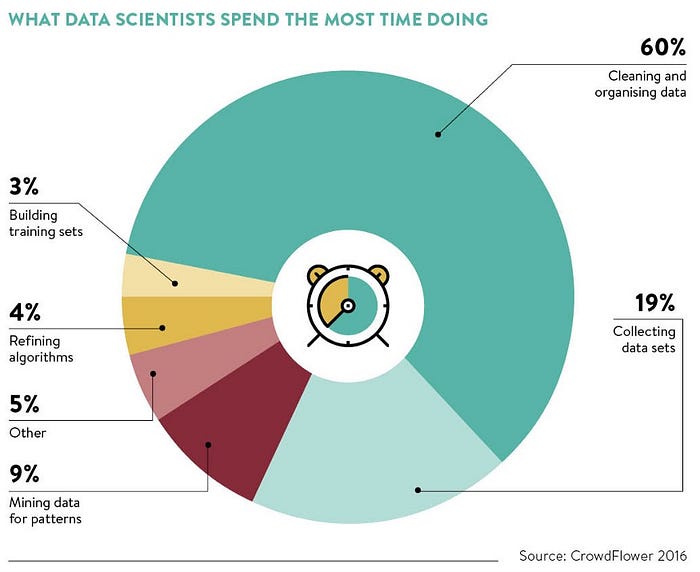
A diferencia de los conjuntos de datos limpios de Kaggle, su propio conjunto de datos le permite desarrollar habilidades en la limpieza de datos y mostrarle a un futuro empleador que está listo para lidiar con conjuntos de datos desordenados de la vida real. Además, puede explorar y aprovechar el ecosistema de Python al aprovechar las bibliotecas que resuelven algunas tareas comunes de limpieza de datos que otros resolvieron antes.
Para mi conjunto de datos de Vielfliegertreff, había un par de tareas comunes como convertir las fechas en marcas de tiempo de pandas, convertir números de cadenas en tipos de datos numéricos reales y limpiar un texto de publicación HTML muy desordenado en algo legible y utilizable para tareas de NLP. Si bien algunas tareas son un poco más complicadas, me gustaría compartir mis 3 bibliotecas favoritas que resolvieron algunos de mis problemas comunes de limpieza de datos:
- dateparser : Analice fácilmente fechas localizadas en casi cualquier formato de cadena que se encuentre comúnmente en las páginas web.
- clean-text : procese previamente sus datos scraping con clean-text para crear una representación de texto normalizado. Este también es sorprendente para eliminar información de identificación personal, como correos electrónicos o números de teléfono, etc.
- fuzzywuzzy : Coincidencia de cadenas difusas como un jefe.
Paso 4: exploración y análisis de datos
Cuando completé un curso de Data Science, me encontré con el Proceso estándar entre industrias para la minería de datos (CRISP-DM) , que me pareció un marco bastante interesante para estructurar su trabajo de manera sistemática.
Con nuestro flujo actual, seguimos implícitamente el CRISP-DM para nuestro proyecto:
Expresar comprensión empresarial planteando las siguientes preguntas en el paso 1:
- ¿Cómo está afectando el COVID-19 a los foros de viajeros frecuentes en línea como Vielfliegertreff?
- ¿Cuáles son algunas de las mejores publicaciones en los foros?
- ¿Quiénes son los expertos a los que debería seguir?
- ¿Cuáles son algunas de las peores o mejores cosas que la gente dice sobre las aerolíneas o los aeropuertos?
Y con los datos extraídos, ahora podemos traducir nuestras preguntas comerciales iniciales desde arriba en preguntas explicativas de datos específicos:
- ¿Cuántas publicaciones se publican mensualmente? ¿Las publicaciones disminuyeron a principios de 2020 después de COVID-19? ¿Existe también algún indicio de que se unieron menos personas a la plataforma sin poder viajar?
- ¿Cuáles son las 10 primeras publicaciones por número de me gusta?
- ¿Quién publica más y también recibe, en promedio, más me gusta por la publicación? Estos son los usuarios que debería seguir regularmente para ver el mejor contenido.
- ¿Podría un análisis de sentimiento en cada publicación en combinación con el reconocimiento de entidad nombrada para identificar ciudades / aeropuertos / aerolíneas generar comentarios positivos o negativos interesantes?
Para el proyecto Vielfliegertreff, definitivamente se puede decir que ha habido una tendencia a la disminución de puestos a lo largo de los años. Con COVID-19, podemos ver claramente una rápida disminución en las publicaciones desde enero de 2020 en adelante, cuando Europa estaba cerrando y cerrando fronteras, lo que también afectó fuertemente a los viajes.
Por último, pero no menos importante, quería comprobar de qué trataba la publicación que más me gustaba. Desafortunadamente, está en Alemania, pero de hecho fue una publicación muy interesante, donde a un hombre alemán se le permitió pasar un tiempo en un portaaviones estadounidense y experimentó un despegue en catapulta en un avión C2. La publicación tiene unas imágenes muy bonitas y detalles interesantes. No dude en consultarlo aquí si puede entender algo de alemán:

Paso 5: comparte tu trabajo a través de una publicación de blog o una aplicación web
Una vez que haya terminado con esos pasos, puede ir un paso más allá y crear un modelo que clasifique o prediga ciertos puntos de datos. Para este proyecto, no intenté seguir utilizando el aprendizaje automático de una manera específica, aunque tenía algunas ideas interesantes sobre la clasificación del sentimiento de las publicaciones en relación con ciertas aerolíneas.
En otro proyecto, sin embargo, modelé un algoritmo de predicción de precios que permite al usuario obtener una estimación de precio para cualquier tipo de tractor. Luego, el modelo se implementó con el impresionante framework streamlit , que se puede encontrar aquí (tenga paciencia con la carga, ya que podría cargar un poco más lento).
Otra forma de compartir su trabajo es como yo a través de publicaciones de blog en Medium, Hackernoon, u otros sitios web populares. Cuando escribo publicaciones de blog sobre proyectos u otros temas, como aplicaciones de IA interactivas increíbles , siempre trato de hacerlas lo más divertidas, visuales e interactivas posible. Estos son algunos de mis mejores consejos:
- Incluya imágenes bonitas para facilitar la comprensión y para dividir parte del texto extenso.
- Incluya elementos interactivos, como tweets o videos que permitan interactuar al usuario.
- Cambie tablas o gráficos aburridos por interactivos a través de herramientas y marcos como airtable o plotly .
Conclusión
Piensa en una idea para una publicación de blog que responda a una pregunta interesante que tuviste o resuelva tu propio problema. Idealmente, el momento del tema es relevante y nadie más lo ha analizado antes. Según su experiencia, la estructura del sitio web y la complejidad, elija un marco que se adapte mejor al trabajo. Durante la limpieza de datos, aproveche las bibliotecas existentes para resolver tareas dolorosas de limpieza de datos, como analizar marcas de tiempo o limpiar texto. Por último, elija cómo puede compartir mejor su trabajo. Tanto un modelo / dashboard interactivo implementado como una publicación de blog mediana bien escrita pueden diferenciarlo de otros solicitantes en el camino para convertirse en científico de datos.
Conoce más de Bootcamp AI
bootcampai.org/python
